In just a few years, the deep learning algorithm has undergone rapid evolution and has reached a level that can defeat the world’s top chess players, and can accurately recognize faces with an accuracy not lower than human recognition.
But facts have proved that mastering a unique and complex human language is one of the most difficult challenges facing artificial intelligence.
Will this status be changed?
If computers can effectively understand all human languages, then this will completely change the way brands, companies and organizations all over the world interact.
A visual recognition model comparable to humans is “first to appear”
It was not until 2015 that an algorithm that could recognize faces with an accuracy comparable to that of humans appeared: the accuracy of Facebook DeepFace was 97.4%, which was slightly lower than the 97.5% of humans.
For reference, the FBI’s facial recognition algorithm only achieves 85% accuracy, which means that more than one in seven cases is still wrong.
The FBI algorithm was manually designed by a team of engineers: each function, such as the size of the nose and the relative position of the eyes, was programmed manually.
Facebook’s algorithm mainly deals with the learned features. It uses a special deep learning architecture called a convolutional neural network, which mimics the way we process images at different levels in our visual cortex.
Facebook is able to achieve such a high accuracy rate because it appropriately uses the architecture that can realize the learning function and the high-quality data of millions of users marking friends in the shared photos. These two elements have become good training. The visual model can reach the key to human recognition level.
Multilingual high-precision language model “Late over”
Compared to visual problems, language seems to be much more complicated-as far as we know, humans are currently the only species that uses complex language to communicate.
Less than ten years ago, artificial intelligence algorithms would only calculate the frequency of specific words if they wanted to understand what text was. But this method obviously ignores the fact that words have synonyms, and they only have meaning in a specific context.
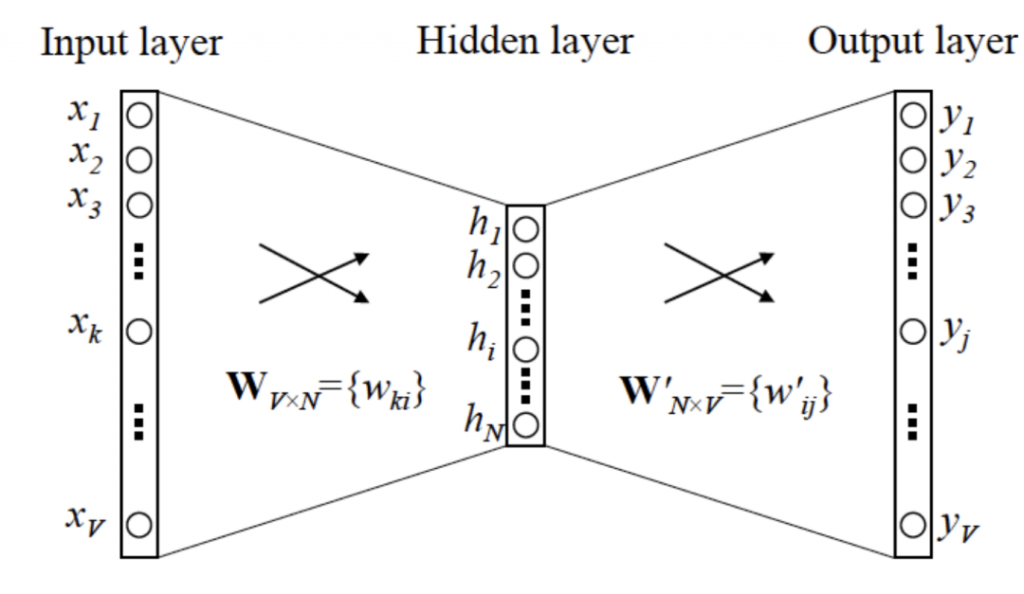
In 2013, Tomas Mikolov and his team at Google discovered how to create a structure that can learn the meaning of words:
Their word2vec algorithm can map synonyms to each other, and can model the size, gender, and speed of synonyms, and can even learn the relationship between functions such as country and capital.
However, there is still a very important part that has not been dealt with-the context (context).
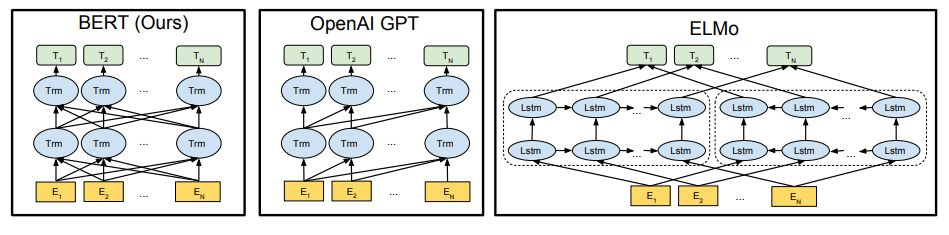
The real breakthrough in this field appeared in 2018, when Google introduced the BERT model:
Jacob Devlin and his team used a typical architecture for machine translation and made it learn the meaning of words related to sentence context. By teaching this model to fill in missing words in Wikipedia articles, the team was able to embed the language structure into the BERT model.
With only a limited amount of high-quality labeled data, they can adapt BERT to a variety of tasks, including finding the correct answer to a question and truly understanding what a sentence is about.
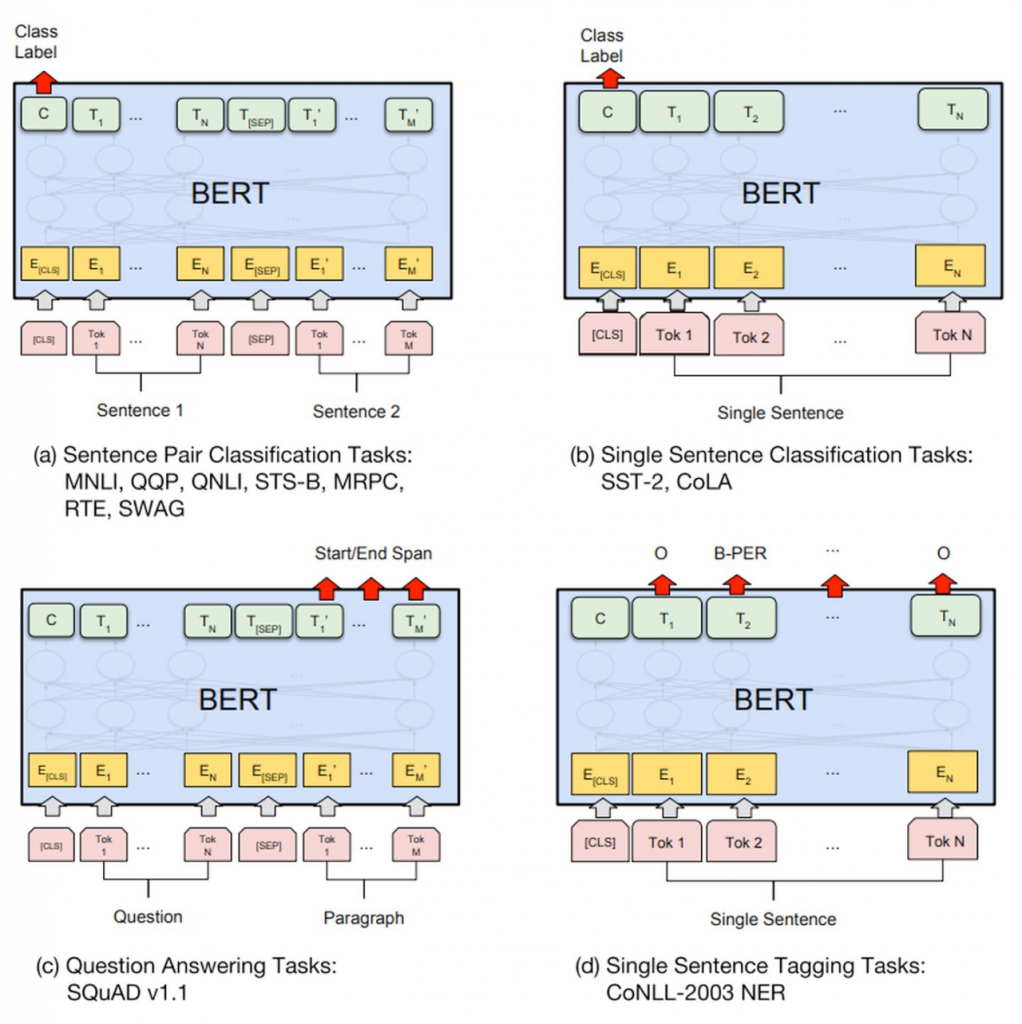
Therefore, they became the first to truly grasp the two elements of language understanding: the correct structure and a large amount of high-quality data.
In 2019, Facebook researchers took this research further:
They trained a model derived from BERT to learn more than 100 languages
at the same time. The result of training is that the model can learn tasks in one language, such as English, and use it to complete the same tasks in any other language, such as Arabic, Chinese, and Hindi.

This language-independent model can have the same performance as BERT in terms of language. In addition, in this model, the influence of some interference in the language conversion process is very limited.
In early 2020, Google researchers were finally able to beat humans in a wide range of language understanding tasks:
Google pushed the BERT architecture to the limit by training a larger network on more data-now, this T5 model can perform better than humans in labeling sentences and finding the correct answers to questions.
The language-agnostic mT5 model released in October is almost as good as bilinguals in terms of the ability to switch from one language to another. At the same time, it has an incredible effect in processing language types-it can handle more than 100 languages at the same time.

The trillion-parameter model Switch Transformer announced this week makes the language model bigger and the effect stronger.
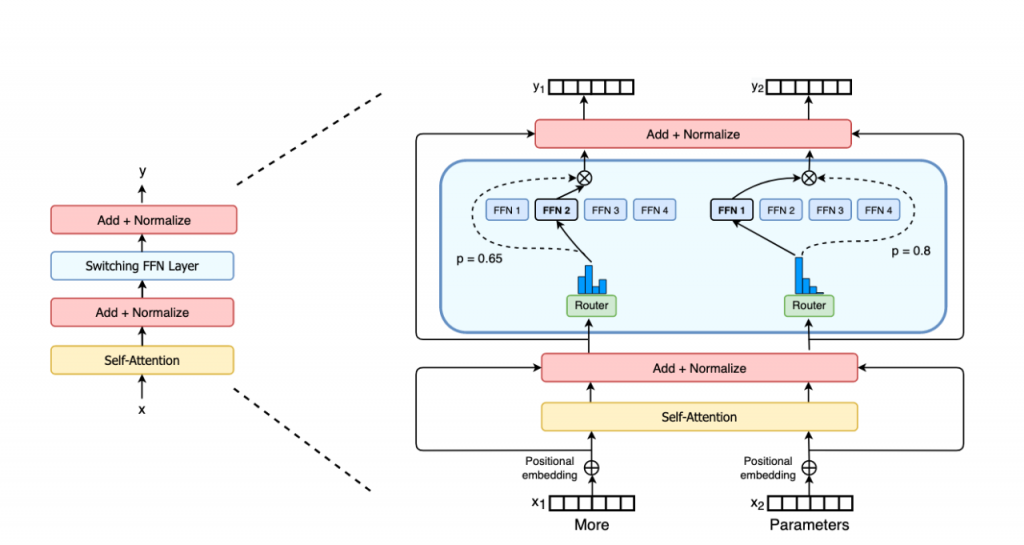
Imagine the future, the language model has great potential
Imagine that the chatbot can understand any idea you have:
They will truly understand the context and remember past conversations. And the answers you will get are no longer general answers, but tangential topics.
Search engines will be able to understand any questions you have:
You don’t even need to use the right keywords, they will give the right answers.
You will get an “AI colleague” who understands all the procedures of your company:
If you know the correct “jargon”, you don’t have to ask other colleagues questions. Of course, no more colleagues will say to you, “Why don’t you read all the company documents and ask me again?”.
A new era of databases is coming:
Say goodbye to the tedious work of structured data. Any memos, emails, reports, etc. will be automatically interpreted, stored and indexed. You will no longer need the IT department to run queries to create reports, just talk to the database.
And this is just the tip of the iceberg——
Any process that still requires humans to understand language is on the verge of being destroyed or automated.
Talk isn’t cheap:
Talk isn’t cheap: a huge language model costs a lot
While building the grand blueprint, don’t forget that there is another “trap” here:
Why are these algorithms not available everywhere?
In general, training these models with high probability will cost extremely expensive prices. For example, the cost of cloud computing for training the T5 algorithm is about $1.3 million.
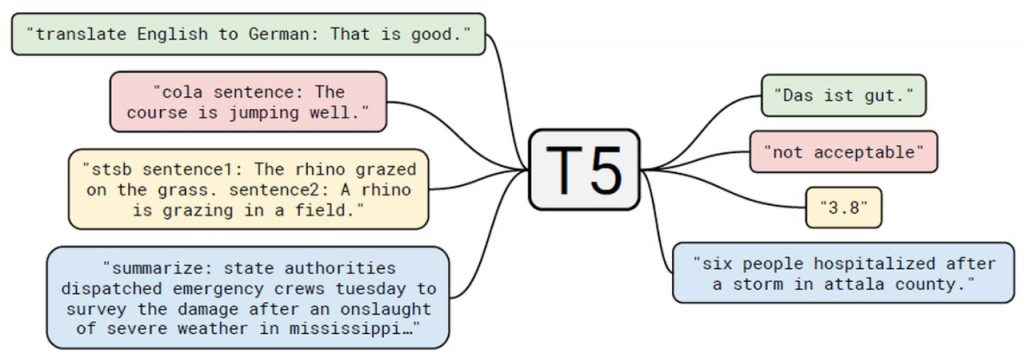
Although Google researchers have shared these models very friendly, but for the current specific tasks, if they are not fine-tuned, then these models may not be used in specific tasks.
Therefore, even if large companies open source these models, it is expensive for others to use them directly.
Moreover, once users optimize these models for specific problems, a large amount of computing power and long time consumption are still required during the execution.
Over time, as major companies invest in fine-tuning, we will see new applications appear.
Moreover, if everyone believes in Moore’s Law, we can see more complex applications in about five years. In addition, new models that can surpass the T5 algorithm will also appear.
At the beginning of 2021, we are only one step away from the most significant breakthrough in artificial intelligence and the infinite possibilities it brings.
Comments